publications
* Denotes equal contribution
2025
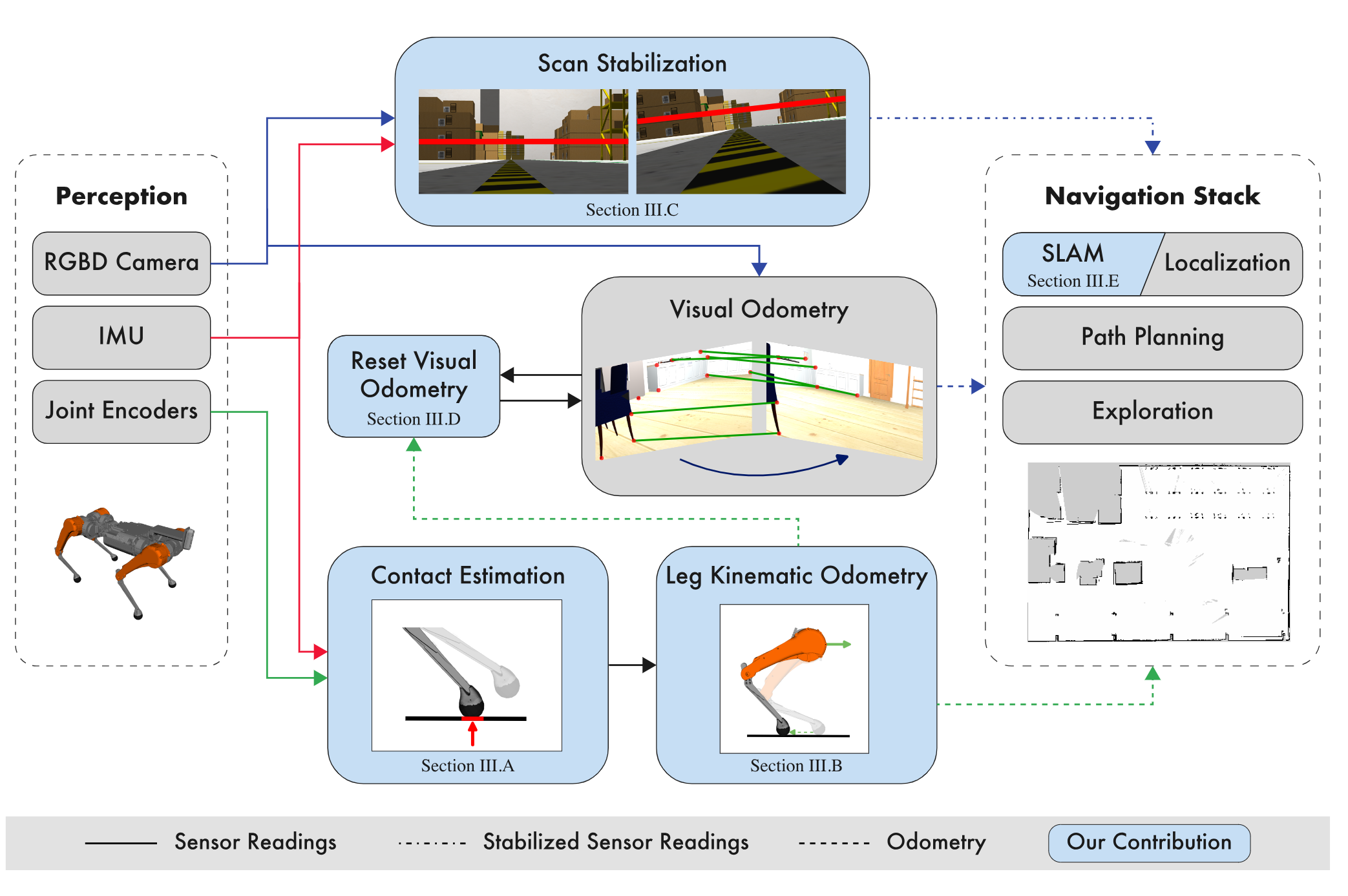
- Robust Localization, Mapping, and Navigation for Quadruped RobotsDyuman Aditya, Junning Huang, Nico Bohlinger, Piotr Kicki, Krzysztof Walas, Jan Peters, Matteo Luperto, and Davide TateoIn ECMR, 2025
Quadruped robots are currently a widespread platform for robotics research, thanks to powerful Reinforcement Learning controllers and the availability of cheap and robust commercial platforms. However, to broaden the adoption of the technology in the real world, we require robust navigation stacks relying only on low-cost sensors such as depth cameras. This paper presents a first step towards a robust localization, mapping, and navigation system for low-cost quadruped robots. In pursuit of this objective we combine contact-aided kinematic, visual-inertial odometry, and depth-stabilized vision, enhancing stability and accuracy of the system. Our results in simulation and two different real-world quadruped platforms show that our system can generate an accurate 2D map of the environment, robustly localize itself, and navigate autonomously. Furthermore, we present in-depth ablation studies of the important components of the system and their impact on localization accuracy. Videos, code, and additional experiments can be found on the project website: https://sites.google.com/view/low-cost-quadruped-slam
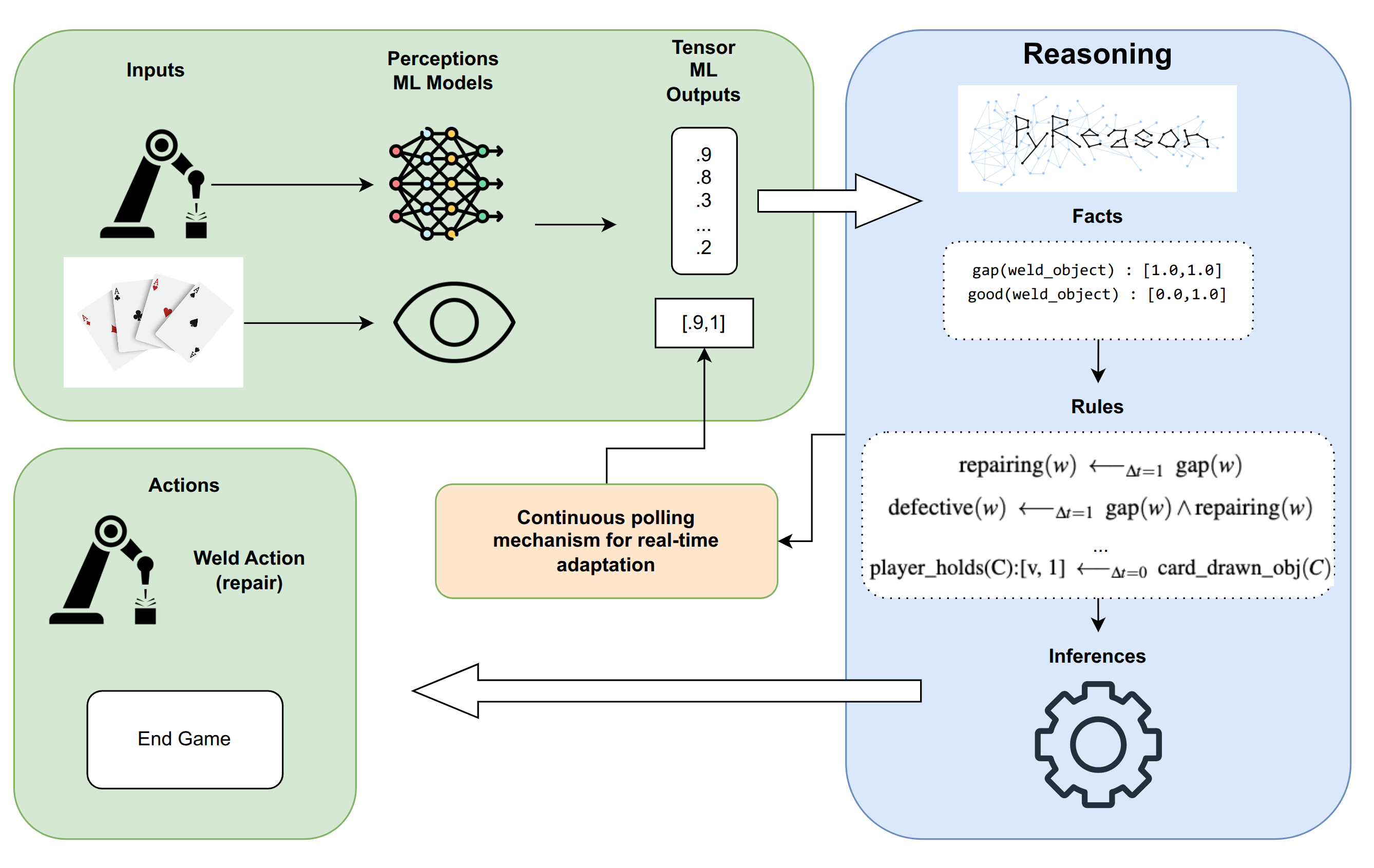
@inproceedings{adityaRobustQuad2025, author = {Aditya, Dyuman and Huang, Junning and Bohlinger, Nico and Kicki, Piotr and Walas, Krzysztof and Peters, Jan and Luperto, Matteo and Tateo, Davide}, title = {Robust Localization, Mapping, and Navigation for Quadruped Robots}, year = {2025}, booktitle = {ECMR}, } - Machine Learning Model Integration with Open World Temporal Logic for Process AutomationDyuman Aditya, Colton Payne, Mario Levia, and Paulo ShakarianIn ICLP, 2025
Recent advancements in Machine Learning (ML) have yielded powerful models capable of extracting structured information from diverse and complex data sources. However, a significant challenge lies in translating these perceptual or extractive outputs into actionable, reasoned decisions within complex operational workflows. To address these challenges, this paper introduces a novel approach that integrates the outputs from various machine learning models directly with the PyReason framework, an open-world temporal logic programming reasoning engine. PyReason’s foundation in generalized annotated logic allows for the seamless incorporation of real-valued outputs (e.g., probabilities, confidence scores) from diverse ML models, treating them as truth intervals within its logical framework. Crucially, PyReason provides mechanisms, implemented in Python, to continuously poll ML model outputs, convert them into logical facts, and dynamically recompute the minimal model, ensuring real-tine adaptive decision-making. Furthermore, its native support for temporal reasoning, knowledge graph integration, and fully explainable interface traces enables sophisticated analysis over time-sensitive process data and existing organizational knowledge. By combining the strengths of perception and extraction from ML models with the logical deduction and transparency of PyReason, we aim to create a powerful system for automating complex processes. This integration finds utility across numerous domains, including manufacturing, healthcare, and business operations.
@inproceedings{adityaMLIntegration2025, author = {Aditya, Dyuman and Payne, Colton and Levia, Mario and Shakarian, Paulo}, title = {Machine Learning Model Integration with Open World Temporal Logic for Process Automation}, year = {2025}, booktitle = {ICLP}, }
2024
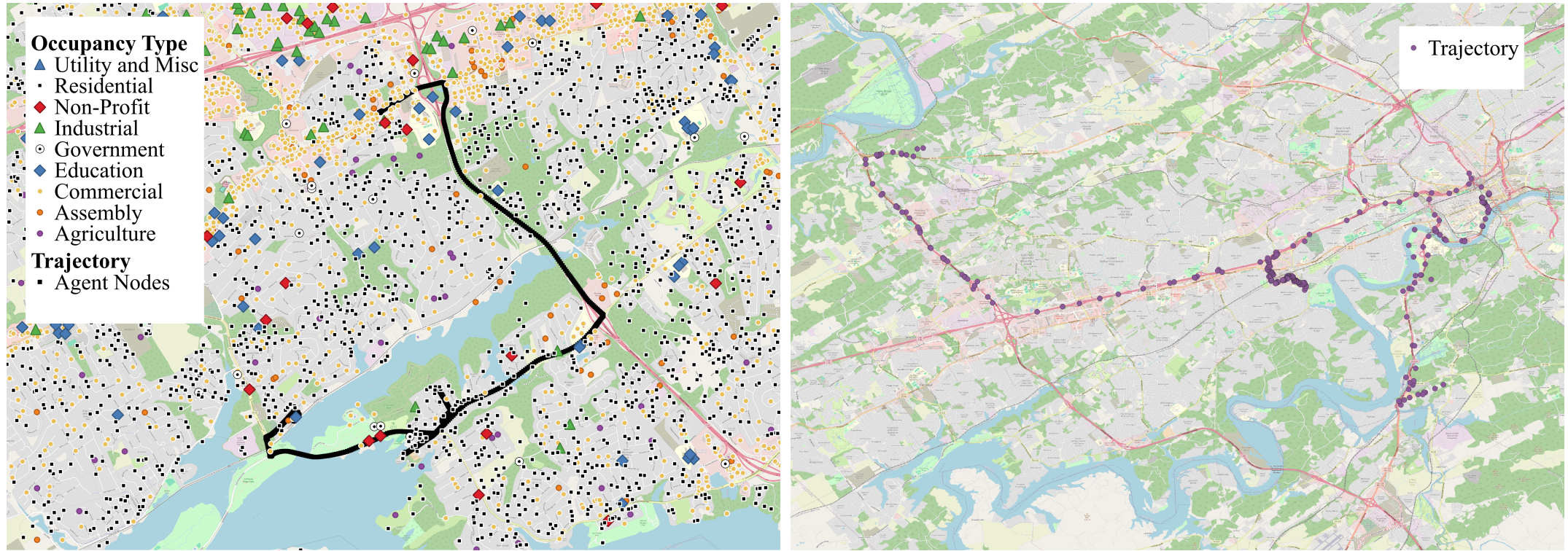
- Geospatial Trajectory Generation via Efficient Abduction: Deployment for Independent TestingDivyagna Bavikadi, Dyuman Aditya, Devendra Parkar, Paulo Shakarian, Graham Mueller, Chad Parvis, and Gerardo I. SimariIn ICLP, 2024
The ability to generate artificial human movement patterns while meeting location and time constraints is an important problem in the security community, particularly as it enables the study of the analog problem of detecting such patterns while maintaining privacy. We frame this problem as an instance of abduction guided by a novel parsimony function represented as an aggregate truth value over an annotated logic program. This approach has the added benefit of affording explainability to an analyst user. By showing that any subset of such a program can provide a lower bound on this parsimony requirement, we are able to abduce movement trajectories efficiently through an informed (i.e., A*) search. We describe how our implementation was enhanced with the application of multiple techniques in order to be scaled and integrated with a cloud-based software stack that included bottom-up rule learning, geolocated knowledge graph retrieval/management, and interfaces with government systems for independently conducted government-run tests for which we provide results. We also report on our own experiments showing that we not only provide exact results but also scale to very large scenarios and provide realistic agent trajectories that can go undetected by machine learning anomaly detectors.
@inproceedings{bavikadi2024geospatialtrajectorygenerationefficient, author = {Bavikadi, Divyagna and Aditya, Dyuman and Parkar, Devendra and Shakarian, Paulo and Mueller, Graham and Parvis, Chad and Simari, Gerardo I.}, title = {Geospatial Trajectory Generation via Efficient Abduction: Deployment for Independent Testing}, year = {2024}, booktitle = {ICLP}, }
2023
- Scalable Semantic Non-Markovian Simulation Proxy for Reinforcement LearningKaustuv Mukerji, Devendra Parkar, Lahiri Pokala, Dyuman Aditya, and Paulo ShakarianIn IEEE ICSC, 2023
Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned. In addition, we show the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.
@inproceedings{mukherji2023scalable, author = {Mukerji, Kaustuv and Parkar, Devendra and Pokala, Lahiri and Aditya, Dyuman and Shakarian, Paulo}, title = {Scalable Semantic Non-Markovian Simulation Proxy for Reinforcement Learning}, year = {2023}, booktitle = {{IEEE} ICSC}, } - PyReason: Software for Open World Temporal LogicDyuman Aditya*, Kaustuv Mukerji*, Srikar Balasubramanian, Abhiraj Chaudhary, and Paulo ShakarianIn AAAI Spring Symposium, 2023
The growing popularity of neuro symbolic reasoning has led to the adoption of various forms of differentiable (i.e., fuzzy) first order logic. We introduce PyReason, a software framework based on generalized annotated logic that both captures the current cohort of differentiable logics and temporal extensions to support inference over finite periods of time with capabilities for open world reasoning. Further, PyReason is implemented to directly support reasoning over graphical structures (e.g., knowledge graphs, social networks, biological networks, etc.), produces fully explainable traces of inference, and includes various practical features such as type checking and a memory-efficient implementation. This paper reviews various extensions of generalized annotated logic integrated into our implementation, our modern, efficient Python-based implementation that conducts exact yet scalable deductive inference, and a suite of experiments. PyReason is available at: github.com/lab-v2/pyreason.
@inproceedings{aditya_pyreason_2023, author = {Aditya*, Dyuman and Mukerji*, Kaustuv and Balasubramanian, Srikar and Chaudhary, Abhiraj and Shakarian, Paulo}, title = {{PyReason}: Software for Open World Temporal Logic}, year = {2023}, booktitle = {{AAAI} Spring Symposium}, }